時系列の予測の技術
目次
最初のステップとして、NNを使った時系列の予測の大まかな図式(図1)を描く。
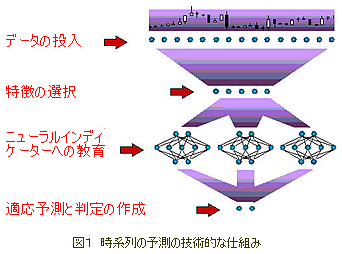
この行程のすべての段階について、少し説明する。
NNモデリングの一般的原理はこの作業に完全に適用できるのだが、金融時系列の予測にはそれ固有の特徴がある。
これらの特徴のすばらしい可能性については後で書く。
投入の技術 Takens(ターケンス)の定理
投入の段階から説明を始める。
私たちが今おそらくわかっているように、予測は”データの補外法により推定すること”に見えるにも関わらず、実はNNは「解の正当性をかなり高めてしまう」”補間法”の問題を解決している。
- *補外法:ある変域内のいくつかの変数値に対して関数値が知られているとき、その変域外での関数値を推定する方法。補間法を変域外に延長して適用するもの。
*補間法:関数の2つ以上の点における関数値を知って、それらの間の関数値の近似値を求める計算法、あるいは間の点における関数値を与えて(補間して)関数を拡張する方法。
時系列を予測することはニューラル解析で出てくるお決まりの課題へと変わる。
これは時系列データを多次元空間へ投入する方法を使って、与えられた例を多変数関数で近似することである。(Weigend, 1994)
例えば時系列 Xt の d次元遅延空間は、d個の瞬間が連続した時系列で構成されている。
![]()
次に述べるTakens(ターケンス)の定理は動的システムへと導入される。
もし時系列データがある動的システムから作り出されているのであれば、Xtの値はそのシステムの状態を示す任意の関数であり、投入深度 d (これは動的システムの自由度の数(有効数字)に等しい)は時系列の次の値をはっきりと予測する。(Sauer, 1991)
- *有効数字:ある数値を示す数字のうち、実際の目的に有効なまたは有意義な桁数を採用した数字
こうして選択したかなり大きな数値dにより、時系列の未来の値とd本前の過去の値との間に明確な依存関係があることを保証できる。
- *このターケンスの定理が「ターケンスの埋め込み定理」のことを意味している場合、
http://chaos.cci-web.co.jp/chaos/attractors.html#takens
ここが少しばかり参考になる。
こうして選択したかなり大きな値dにより、時系列の未来の値とdだけ前の過去の値との間に明らかに依存関係があることを保証できる。
これは
![]()
と表せる。
つまり、時系列の予測は多変数関数の補間法の課題へと変化する。
そしてこの時系列の過去のデータに基づいて作られるこの未知の関数を復元することにNNを使うことができるのである。
これとは反対にランダムな時系列では、過去のデータについての知識は未来を予測するために役立つヒントを与えてくれない。
そのため効率的市場仮説によれば時系列の予測値の分散は遅延空間へ投入しても変化しない。
(遅延空間へ)投入したカオス的動きと確率的(ランダムな)動きの違いを図2に表した。
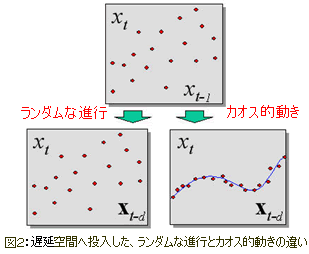
- *図の「ランダムな進行」は「ランダムな増加」と訳すべきかもしれない。
Incremet(インクリメント)はプログラム用語では変数の値を1ずつ増やすという意味があり、ソフトウェア上でランダムに点を増やしていると言う意味であれば、そうなる。
時系列予測の可能性についての実験による立証
投入の方法により実際の有価証券(金融商品)の予測可能性を定量的に測定できる。
つまり、効率的市場仮説が正しいもしくは正しくないことを証明することが可能である。
この仮説に賛成の立場に立つと、(もし点が一様に分布し各点がそれぞれ独立したランダムな数値であれば)すべての遅延空間座標の点の分散はまったく同じである。
反対に、特定の予測可能性を与えるカオス的動きをする各点は、特定の超曲面![]() の周りで観測されなければならない。
の周りで観測されなければならない。
言い換えれば、実験サンプルは遅延空間全体の次元よりも小さな次元を形成する。
次元を測定するために、次の直感的性質を利用することができる。
もし集合体が次元Dをもつのであれば、その次元はεという面で作られた立方体に小さく分解されそしてその立方体の数はεのマイナスD乗にまで増えることになる。
この事実は(前記の考察から知った)”ボックスカウント法により集合体の次元を検出すること”が基礎となっている。
点の集合体の次元はすべての点を内包する立方体の数が増える早さによって検出される。
このアルゴリズムを加速するために、ε次元を2の倍数として利用する。言い換えれば分解の規模は(0,1の)ビットとして測定される。
典型的なマーケットの時系列の一例として、NY取引所の平均価格の動きを反映しているS&P500インデックスを使ってみよう。
図3は679ヶ月の期間のインデックスの動きを表したものである。
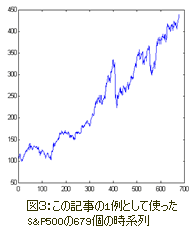
この時系列の増加の次元(情報次元を意味したもの)をボックスカウント法によって計算し表したものが図4である。
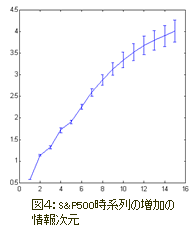
図4によれば、このサンプルから点は約4次元の集合体を15次元投入空間に形成する。
これは独立したランダムな数値の増加として時系列の増加を考えている効率的市場仮説を基に得られる数15よりも小さい。
こうにして実験によって得られたデータは、金融時系列にある程度の予測可能な要素が存在する確たる証拠を示している。ただしカオス的動きがここに存在することが完全に決まったとは言えない。
したがってマーケット予測にNN解析を適用する試みは強い理由に基づいたものとなった。
しかしながら理論的予測可能性が「予測が実用的で意味のあるレベルに到達できること」を証明していないことには注意すべきである。
特定の時系列の予測可能性についての定量的評価はクロスエントロピーの測定により行える。
この方法でもまたボックスカウンティング法を使うことができる。
例えば、投入深度に関連したS&P500の増加の予測可能性を測定することは可能である。
クロスエントロピーは
![]()
であり、これを表したのが次の図である。
図の横軸は投入空間の次元数、縦軸は点の集合体の次元数を意味する。
d個前の時系列の値を知ることによって、(時系列の)次の値に追加された情報を測定している。
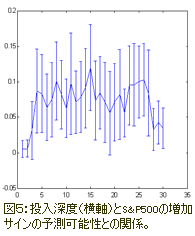
投入深度が25を超えると、予測可能性は次第に減少しているようである。
予測可能性が実際にこのレベルに到達できるように、さらに評価をしていこう。
特性(属性)についての入力空間を形成する
図5では、時系列の投入の値が増えても最終的に予測可能性は減少する結果となることがわかる。
ただしこれは入力次元を増やすことがもはや次元の情報の値によって補われない時に、である。
- *英語原文自体が意味不明の文章。
このケースではもし遅延空間の次元dが与えられた例の数よりはるかに大きな場合、特質(属性)についての空間をより小さな次元で構成する特別な方法を使わなければならない。
特質(属性)を選択するためのそして(または)利用可能な例の数を増やすための金融時系列特有の方法を次に書く。
誤差(汎)関数の選択
- *関数を変数に取る関数はとくに汎関数(functional)という。誤差関数とはガウス分布 あるいは正規分布とも呼ばれる。
NN学習を行うためには、入力と出力のための教育用データを作ることだけでは不十分である。
ネットワーク予測のエラーが検出されるはずだ。
大部分のNNアプリケーションがデフォルトで使っている二乗平均平方根(RMS)エラーは、マーケット時系列のための十分な”金融のセンス”をもっていない。
これがこの記事の中で、我々が何故金融時系列の誤差の特性を考えそしていかにこの誤差が予想される収益率と関係があるのかを示す理由である。
例えばマーケットポジションを選択するためにはレート変化のサインの確実な検出が平均二乗偏差よりも重要だ。
これらの指標は互いに関連があるが、このうちの1つ(のみ)に最適化されたネットワークはもう1つの指標に悪い予測を与えることになる。
(この記事をさらに進めていくために)適切な誤差関数を選択するには、明確な理想的戦略に基づきさらに最大利益(または最小損失)といった目標(希望)を決定する必要がある。
ニューラルネットワーキングの学習
時系列予測の主な特徴的な機能はデータプリプロセッシング(pre-processing)分野にある。
それぞれのNNに学習させる工程は標準的なものである。
一般的に、利用可能な要素は3つのサンプル”学習、認証、実験”へと分けられる。
1つめはネットワークの学習に使用され、2つめは最適化されたネットワーク構造の選択および(または)ネットワークへの教育をストップする時を選択することに使用される。
最後の3つめは教育にはまったく使用されず、”学習した”NNの予測精度を調整するための役割をもつ。
しかしながらノイズがかなり多い金融時系列にとって、同じグループのNNを利用すること(*フィードバックNNのことか?)は、予測の信頼度で有意義な収穫を得る(大きく利益を得る?)結果へとつながる。
この技術についての話はここでやめることにする。
いくつかの調査によれば、フィードバックNN(=リカレントNN)の利用による予測精度の向上が証明されていることがわかっている。
このネットワークは入力データとして明らかに利用可能なものよりさらにもっと過去のデータをローカルメモリにもつことができる。
しかしこのような構造を考えることは本題からそれることになり、次に述べる特別な時系列投入の技術により効率的にネットワークの【層】を拡張するいくつかのほかの方法が存在する(ためフィードバックNNについての話題はとりやめる)。
(特性)属性の空間の形成
入力の効率的なコーディングは予測の質を高めるキーとなる。
困難な金融時系列の予測可能性にとっては特に重要である。
データプリプロッセッシングに標準的に要求されるすべてのことにも当てはまる。
データプリプロッセッシングの方法には金融時系列特有のものが存在する。
この章ではより詳しく考えることにする。