WEKAを使ったデータマイニングの結果から、データを絞り込むことが必要なことがわかった。
そこでプログラムを自作してデータの抽出を実行した。
抽出の手順
目次
条件によるデータの選別
尖度・歪度の頂点を中心とした付近を拡大してヒストグラムを観察することが、WEKAで可能であるかはわからない。
(もしくはないのかもしれない)
そこで以下の方法をとることにした。
まず、WEKAで見たヒストグラムから、絞り込む条件を決める。
具体的には、尖度・歪度のそれぞれについていくつの数値以下(or 以上)のものを抽出したいのかを決定する。
「CSVファイル内の指定した条件に該当するレコードとそうでないものを選別し、それぞれ2つの新しいCSVファイルとして作成する」(抽出とも選別ともいえる)プログラムを自作し使用する。
そして作成されたCSVファイルをWEKAで見る。
このプログラムは 07_Export_Data_from_CSV.exe という名前だが、「CSVファイルのレコードのフィールドを指定して、条件を設定し、抽出する」という作業は今回だけでなく他の目的にも応用できるものだ。
ここからダウンロードできるが、zip形式で圧縮されているので解凍する。
お決まりの文句ですが、このプログラムは私個人用に作ったものであるため、使用する人は自己責任でお使いください。
不具合がある可能性もあり、動作を保障するものではありません。
以下にこのプログラムの使い方を説明する。
CSVファイル内のレコードをフィールドの条件で抽出するプログラム
- 07_Export_Data_from_CSV.exe のアイコンをダブルクリックして起動する。

- 次のウィンドウが現れるのでDestinationのボタンをクリックする。
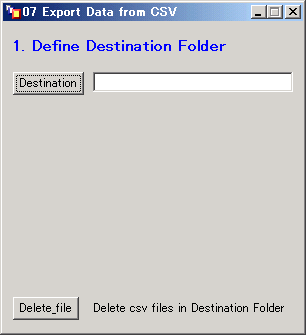
- 作成されるCSVファイルを保存するフォルダ(ディレクトリ)を指定する。OKボタンをクリックする。
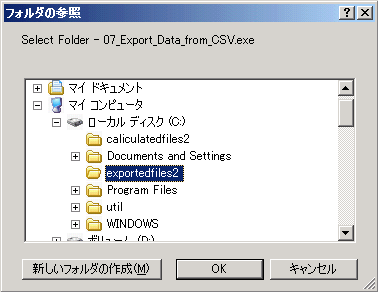
- csv_fileのボタンをクリックする。
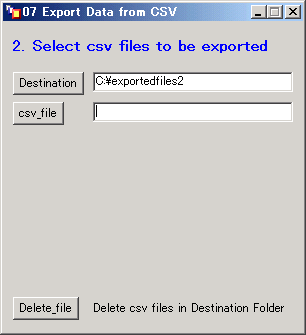
- 選別(抽出)したいCSVファイルを選択する。
そして「開く(O)」ボタンをクリックする。
今回はCalcResult.csvを選択する。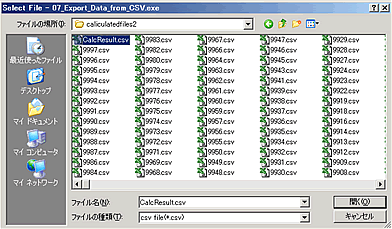
- 抽出(選別)する条件を設定する。
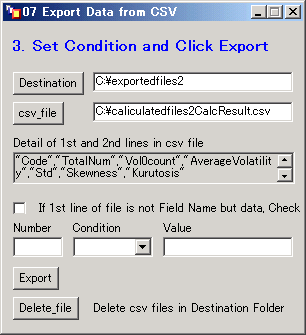
Detail of 1st and 2nd lines in csv fileの下にあるフォームに05.で選んだCSVファイル(複数個ある場合は1つめのファイル)の1行目と2行目が表示される。
通常CSVファイルの1行目はフィールドが書かれているが、場合によっては1行目からデータとなっているファイルもある。
後者の場合は、If 1st line of file is not Field Name but data, Check の横のチェックボックスにチェックをつける。次にフィールドの番号をNumberの下のフォームに入力する。番号は左から1,2、、と数える。
ここでは例として”kurtosis”のフィールドを選択するため、フォームには半角で7を入力する。Conditionの下のメニューから条件を選択する。条件は次のとおりとなる。
-
If Value is :これはフィールドの値がValueの下のフォームに入力した値と同じものを抽出する。
If Value <> :これはフィールドの値がValueの下のフォームに入力した値と同じでないかものを抽出する。
If Value < :これはフィールドの数値がValueの下のフォームに入力した数値未満のものを抽出する。 If Value > :これはフィールドの数値がValueの下のフォームに入力した数値より大きいものを抽出する。
If Value <= :これはフィールドの数値がValueの下のフォームに入力した数値以下のものを抽出する。 If Value >= :これはフィールドの数値がValueの下のフォームに入力した数値以上のものを抽出する。
今回はkurtosis(尖度)が75以下のものを抽出したいため、If Value <= と 75 を設定する。
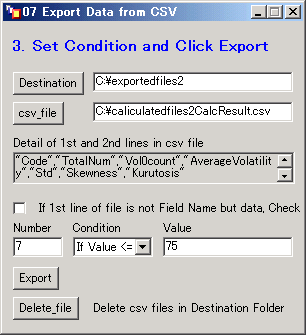
Exportのボタンをクリックする。
- Choosing from ファイル名 のメッセージが出て抽出が実行される。
- 抽出が終了すると、作業にかかった時間が表示される。OKボタンをクリックする。
- Finished のメッセージが表示される。
Reload ボタンで再実行(02から作業を行う)できる。
また、Delete_file ボタンはDestinationで選択したフォルダ内のCSVファイルをすべて削除するときに使用する。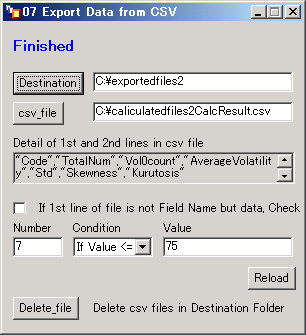
- 作成されたファイルは次のようになる。
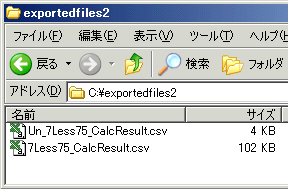
今回の例ではCalcResult.csvから2つのファイルが作成された。
抽出されたものが7Less75_CalcResult.csvで、抽出されなかったものがUn_7Less75_CalcResult.csvとなっている。抽出といいつつ、結果的には2つのファイルに選別しているのだ。
名前は
「フィールド番号」「条件(Condition)」「条件の値(Value)」_「抽出元のファイル名」
というルールでつけられる。
抽出されなかったものの名前はさらにこの名前の前に
Un _ がつく。これで作業は終了となる。