これら指標のための追加コードは本書61,62ページにあるが、ここではすこし変更してある。
{ *********** calculate performance ****************** }
Vars:
FName(""), TotTr(0), Prof(0), CumProf(1),
ETop(1), TopBar(0), TopInt(0), BotBar(0), BotInt(0),
EBot(1), EDraw(1), TradeStr2("");
if CurrentBar = 1 then begin
FName = "C:\Temp\" + LeftStr(GetSymbolName,2) + ".csv";
FileDelete(FName);
TradeStr2 = "E Date" + "," + "Position" + "," + "E Price" + "," +
"X Date" + "," + "X Price" + "," + "Profit" + "," +
"Cum.prof." + "," + "E-Top" + "," + "E-Bottom" + "," +
"Flat time" + "," + "Run up" + "," + "Drawdown" + "," +
"PointValue" + NewLine;
FileAppend(FName,TradeStr2);
end;
TotTr = TotalTrades;
if TotTr > TotTr[1] then begin
Prof = 1 + PositionProfit(1)/(EntryPrice(1)*BigPointValue);
CumProf = CumProf * Prof;
ETop = MaxList(ETop,CumProf);
if ETop > ETop[1] then begin
TopBar = CurrentBar;
EBot = Etop;
end;
EBot = MinList(EBot,CumProf);
if EBot < EBot[1] then BotBar = CurrentBar;
TopInt = CurrentBar – TopBar;
BotInt = CurrentBar – BotBar;
EDraw = CumProf / Etop;
TradeStr2 = NumToStr(EntryDate(1),0) + "," +
NumToStr(MarketPosition(1),0) + "," +
NumToStr(EntryPrice(1),2) + "," +
NumToStr(ExitDate(1),0) + "," +
NumToStr(ExitPrice(1),2) + "," +
NumToStr((Prof - 1)*100,2) + "," +
NumToStr((CumProf - 1)*100,2) + "," +
NumToStr((ETop - 1)*100,2) + "," +
NumToStr((EBot - 1)*100,2) + "," +
NumToStr(TopInt,0) + "," +
NumToStr(BotInt,0) + "," +
NumToStr((EDraw - 1)*100,2) + "," +
NumToStr(PointValue,2) + NewLine;
FileAppend(FName,TradeStr2);
end;
このコードをStrategyのEasyLanguageプログラムの最後に追加することでバックテスト時にCドライブのTempフォルダ内にExcel対応のファイルができる。
Tempフォルダがない場合は自分でフォルダを作る。
そうでないとExcel対応のファイルができない。
次に、できた(出力された)ファイルをExcelまたはExcel互換ソフトで開く。
今回はExcel互換ソフトのフリーウェアOpenOfficeのCalcで開いた。
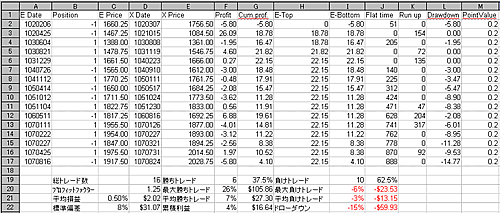
62-65ページの説明をもとに開いたスプレッドシートで、各指標の計算式をセルに入力していく。
説明文で少しわかりにくい部分がある。(そのままではエラーがでるところもある。)
例えば62ページの
パーセンテージベースの平均利益は、C(X+4)のセルに次の公式を入力する。
= AVERAGE(F$2:FX)/100
Fは、各トレードの利益を保存した列を表す。Xは、行番号またはトレード数を表す。
これをもう少しわかりやすく、下にある実際のスプレッドシートで説明する。
パーセンテージベースの平均利益とは63ページの表2.1検証結果の例にある平均損益のこと。
F列はProfitと書かれた列のこと。
Xは最後のトレードの行番号、つまりここでは17となる。
よって式は
= AVERAGE(F$2:F17)/100
となる。
このような作業を各指標について行う。
(新たな出力ファイルで同じことをするときには最後のトレードの行番号が変われば、各セルの式のXに相当する数字も変更しなくてはいけないのは少し面倒。)
下図のように指標の一覧を表2.1検証結果の例と同じ表示にするためには、本に載っていない細かい変更作業が必要。
(必須ではない)
本書では最適化の行程とその種類ごとに章として区切り、その章ごとにいくつかのStrategyについて例をあげて説明している。
しかしこの方法では、最適化の一連の流れをつかむにはわかりにくいため各Strategyごとにどのように最適化を行ったのかを概略をまとめてみる。
ヒストリカルデータから平均上昇・下落期間、平均上昇・下落幅などを算出し、統計値を参考にシステムを構築。実際にはS&P 500の日足の終値のヒストリカルデータ(RAD)をExcelに取り込み、Excel上で上昇・下降の期間の長さやその大きさについてのデータマイニングを行った
↓
データマイニングの結果をもとにStrategyを作成し(101ページ)、S&P 500のRADでバックテストをおこなった。
その結果をExcelに取り込み、指標を算出した。
その結果が表5.4と5.5である。
結果は悪くないが、この戦略が単に統計データを利用したものにすぎず、統計上の傾向が将来も続くという前提にたっている。しかし統計データによる月ベースの動きは年数がたつごとに大きくなっておりまたそのトレンドの長さも変化しているため、この前提は成り立たない。
ゴールドディガーⅠの結果から、短期の統計データでの年数による差はわからないが、長期の統計データでは変化があることがわかった。
見方を変えると、将来にわたってバックテストと同じように機能するトレーディングシステムを構築するためには、短期の見通しに集中しトレード期間も短期のものとする。
このことから長期=月足についての条件をはずした。
その結果は表5.6となり、標準偏差はより低いものとなった。
↓
第11章。記述統計学を使った解析により改良をめざす。
ゴールドディガーⅡのストップが現在の反対方向のトレードを行うということ以外存在しないことから新たなストップを追加することを検討。
トレード期間を短期にする=5日のトレード時間リミットを追加。
S&P 500のRADでバックテスト(表11.1)しExcelで指標算出。
↓
具体的な説明なしに表11.2。
図11.4では横軸にリターン縦軸に発生頻度のグラフ”リターンの分布”。
このグラフが正規分布でないためチェビシェフの定理と歪度がプラスということから、グラフ上の大きな利益と大きな損益を切るラインを決める。
そしてその値をリミットストップ、ストップロスとしてStrategyにコードを追加する。(287ページ)
しかし、この説明(286ページ)は理解できなかった。
↓
S&P 500のRADでバックテストしExcelで指標算出。
そして平均値(平均損益)、中央値、尖度、歪度、トリム平均も算出。
そしてリターン分布のグラフも描いた。(表11.3~11.6)
↓
改造するほど、結果がよくない。
突然著者は古いヒストリカルデータでバックテスト。
この結果は意外にもよいものであったため、その原因を解析。
古い期間ではシステムがうまく機能するようなマーケットの状態であったと結論。
↓
今後この改造後のStrategyをゴールドディガーとよぶ。
↓
317ページ。
ブラックジャックの手仕舞い(ランダムなエントリー下での効率的な手仕舞い)をゴールドディガーに使用し、S&P 500のRADでバックテストしExcelで指標算出。
↓
第12章フィルタリング。
表12.4にある10種類のフィルターをそれぞれ追加してS&P 500でためし、最も成績がよかったレシオクロスフィルターで指標算出。
そしてブレイクアウトフィルターを追加した場合の指標算出。
↓
ゴールドディガーの仕掛けの条件で”2週間”を”1週間”に変更。これにより、より多くのトレードを実行するようになった。
この本ではS&P 500用に設計しその結果を出しているが、実際の検証は他の15のマーケットでも行ったとのこと。