データマイニングでは、クレンジングといわれる「準備したデータから必要なものだけを抽出して、場合によっては加工する」作業が必要となる。
これまでの作業(国内マーケットデータを準備する)で国内マーケットデータについてコード毎のCSVデータを準備が完了した。
データマイニング(もしくはデータ解析)により国内マーケットにある特徴をみつけトレードに利用することを目的としているが、準備したマーケットデータはあまりに数が多い。
そのため不必要なデータはできるだけ取り除く方がいいだろう。
ここで”不必要なデータ”について考えてみる。
まず、「現在存在しない銘柄=トレードできない銘柄」。
ただし上場廃止になる傾向を解析する場合は反対にこれのみに絞ってもいいかもしれない。
「取引日数が少ない=日の浅い銘柄」。
データ日数が多いほど解析結果の信頼度は上がる、他大半の銘柄と同程度の取引日数、と考えるとこうなる。
ただし上場して間もない銘柄の傾向を解析するならば、反対にこれのみに絞ることになる。
「流通量が少ない、取引の少ない銘柄」。
出来高や高値と安値の幅などで判断できるかもしれないが、現時点ではその基準がないため、削除できない。
「高価な大型株=資金不足の問題でトレードできない銘柄」。
データマイニングの対象からはずしていいかわからないため、現時点では対象データに含めることにした。
以上の不必要なデータ=不必要なコードのCSVファイルを削除するために、
”「データ倉庫」の任意のデータファイルを参照して、そのファイルに載っているコード銘柄のCSVファイルのみ抽出(移動)する”、
ことにした。
これを行うために新たにプログラムを自作した。
復習となるが、データ倉庫のデータファイルは日付ごとのテキストファイルであるため、そのファイルを参照することは、その日付の時点で存在する銘柄を選択することを意味する。
例として2000/01/04から現在まで存在する銘柄を抽出するのであれば、このプログラムを2度使い、1回目は2000/01/04で存在する銘柄と2回目は2008/08/01で存在する銘柄をそれぞれデータ倉庫のファイル000104.txt と 080801.txt を参照にする。
自作したプログラムの名前は 05_Choose_stocks_by_Index.exe とした。
ここからダウンロードできるが、zip形式で圧縮されているので解凍する。
お決まりの文句ですが、このプログラムは私個人用に作ったものであるため、使用する人は自己責任でお使いください。
不具合がある可能性もあり、動作を保障するものではありません。
以下にこのプログラムの使い方を、「2000年年始~2008年7月末まで存在する銘柄を抽出する」
のを例にしてデータを説明する。
データクレンジング1~データ倉庫ファイルを使ったデータの抽出
- 05_Choose_stocks_by_Index.exe のアイコンをダブルクリックして起動する。

- 次のウィンドウが現れるのでDestinationのボタンをクリックする。
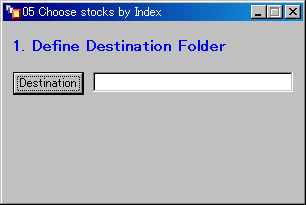
- CSVファイルの抽出(移動)先となるフォルダ(ディレクトリ)を指定する。
OKボタンをクリックする。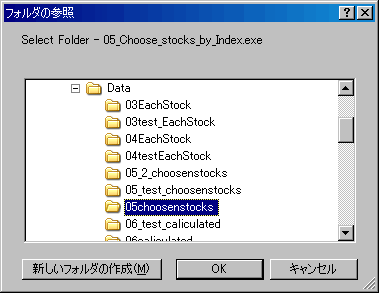
- csv_fileのボタンをクリックする。
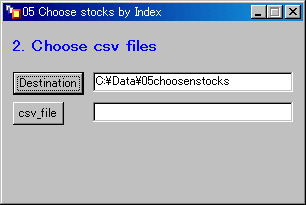
- 作成済みの国内マーケットデータ(コード毎のcsvファイル)を選択する。
そして「開く(O)」ボタンをクリックする。
メモリーもしくは字数制限が原因と思われる理由で、データをすべて選ぶとエラーが出る場合がある。
その場合は選ぶデータを2つか3つに分けて2~11の作業を繰り返し行う必要がある。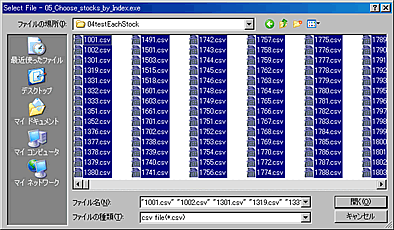
- DataSoukoボタンをクリックする。
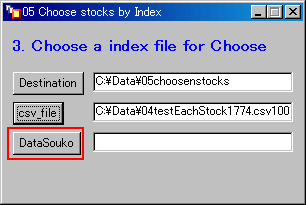
- 「データ倉庫」のファイル、d000104.txtを指定する。
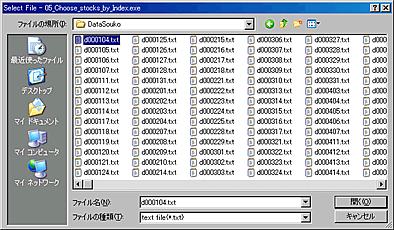
- Choose のボタンをクリックする。

- Dividing from コード のメッセージが出て抽出が実行される。
- 変換・作成が終了すると、作業にかかった時間が表示される。
OKボタンをクリックする。
- Finished のメッセージが表示される。
- 2000/01/04に存在するすべての銘柄のファイルの抽出(移動)が終了したら、Reloadボタンをクリックし、今度はデータ倉庫のファイル080731.txtを使って2008/07/31に存在する銘柄のファイルの抽出を行う。
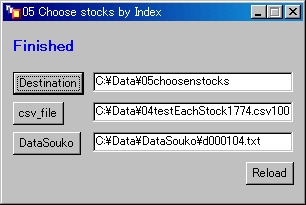
工程2で新たな移動先のフォルダ、工程3で000104.txtで抽出(移動)したファイルを指定する。
- すべてのファイルについて抽出が終われば作業は終了となる。
終了する場合はウィンドウ右上のクローズボタンをクリックする。
続けて作業する場合は Reloadボタンをクリックする。
これでベースとなるデータの準備・クレンジングの説明は終了だ。
皆さんにはブラックボックスではあるが、自作プログラムにより複数のデータを一括して加工処理できることがわかったと思う。
そしてすでに説明した3つの作業、
データ倉庫からデータのダウンロード、
データからcsvファイルの作成、
データクレンジング1~データ倉庫ファイルを使ったデータの抽出
を行えば、各銘柄のデータの期間をほぼ同じに揃えることができる。
しかしここまで加工しても、対象銘柄すべてを一括してデータマイニングを行うことはできない。
「取引されている日数が少ない」銘柄がまだ除外できていないのだ。
ここで「なぜ対象銘柄を一括してデータマイニングしたいのか?」ということについて触れておくと、「国内マーケット(株式)全般に共通する傾向があるのかを調べたい」ためである。
もしひとつの銘柄のデータについてデータマイニング(解析)を行いある傾向をみつけたとしてしても、それがその銘柄のみの傾向かもしれず、またはあたかもカーブフィッティングのようなあやまった解析をしてしまっている可能性がある。
データからみつけた傾向が銘柄大半についてもあてはまると判断するには、当然他の銘柄についても同じ解析作業を行う必要がある。
もしかしたらその地道な作業をするしか方法がないのかもしれないが、それは今の時点ではわからないので試行錯誤しているわけだ。
全銘柄を一括してデータマイニングするにはデータマイニング用ソフトウェアがデータをどう取り扱うのかを考えなければいけない。
データマイニング用ソフトウェア=データウェアハウスでは、1つのデータのことを1レコードといい、レコード内の各項目をフィールドという。
現時点までの作業では、すべてのデータは、1銘柄(コード)ごとにつき1つのファイルとして存在し、ファイル内には複数のレコードが書かれている。
そして1レコードは1行で書かれ、フィールドとして、
日付 , コード , 始値 , 高値 , 安値 , 終値 , 出来高
がある。
今回使用するデータマイニング用ソフトウェアのWEKAでは、ファイルに書かれた各レコード(各行)はそれぞれ独立したものと認識される。
時系列順に関連づけをしてくれない。
そして、もしすべての銘柄の時系列データ(すべてのファイル)を1つのファイルにまとめたとしても、WEKAは同じ銘柄のデータをグループとして自動で認識しまとめてくれはしない。
WEKAを使って銘柄全般に共通する傾向をみつけたいのであれば、まず各銘柄のレコードはそれぞれ1行にした上で、それを1つのファイルにまとめる必要がある。
トレーダーにとってもっとも望むこと、
「1つの銘柄の時系列データからある傾向をみつけ、その傾向が他の銘柄の時系列データでもみられるのかを自動で調べてくれる」
ことまではWEKAはしてくれない。
複数のファイルを一括して解析するには、再びプログラムを自作して行う方法しか今のところなそうだ。
これ以降の段階はアイデアの考案・試行となるだろうから、とにかく実際に何かやってみることにする。